CPP
- Tags
- language
Is a low level programming language and exists as the mostly backwards-compatible
successor to C.
Initially standardised in 1998, c++ has had several revisions. A minor revision in 2003, followed by a large overhaul in 2011 and gradual improvements every 3 years from then on-wards.
Deviations from C
Function Overloading and Name Mangling
The CPP compiler mangles the names of any identifiers and symbols in the produced object files. This is to handle functional overloading, where a function can be declared with different types and the compiler can resolve the correct function depending on the argument types.
#include <iostream>
void foo(void) {
std::cout << "Nothing" << std::endl;
}
void foo(const char* string) {
std::cout << "Something: " << string << std::endl;
}
int main() {
foo();
foo("Hello");
return 0;
}foo.In C each symbol in the object file must be uniquely defined. Because CPP originally compiled down to C so it imposes this restriction on the generated object files as well. The way CPP handles this is by having different symbols than what's defined in the source code and then resolves the correct target symbol depending on the provided argument types. The output of the name mangler is deterministic, meaning the same function with the same parameters will always have the same mangled output.
Note: Two functions with the same identifier can also have two different return types. So long as they different in the number of parameters or their types, it's sufficient.
Overloaded Function Pointer Resolution
At compile time C++ must resolve each function call to a function definition. The rules for this grow more unpredictable with overloads and implicit casts. The stages the compiler follows for function resolution are:
- Filter on name
- Filter on number of arguments
- Filter on best match
Resolution fails if no function or more than one function matches the function call.
| Conversion | Example | Notes |
|---|---|---|
| Exact Match (no temporary) | Adding reference, const | Prefers casting T -> T& over T -> const T& |
| Promotion | short -> float, float -> double | |
| Built-In | float -> int | |
| User-Defined | Single argument constructor | |
| User-defined and Built-in | 4.0 + Number(38) |
Declaration, Definition, Initialisation and Assignment
Beyond the classic declaration and definition concepts inherited from C, CPP also divides the assignment step into initialisation and assignment. If you assign a variable at the same time you declare it, you've done an initialisation. If you later reassign that variable to a new value, you've assigned it (not re-initialised it).
void foo() {
// Declaration, definition and *default* initialisation.
std::string foo;
// Declaration, definition and initialisation.
std::string bar = "";
// Assignment
foo = "blarg";
}Note: This distinction applies even in situations you may not expect. Passing values to a function results in them being copied into a new stack-frame meaning their re-initialised within the context of that function.
Default Parameter Values
C++ introduced default parameter values. You specify the defaults at declaration time (in the header files) and omit the defaults in the definition.
int currentYear();
double contractValue(std::string name,
char expiryMonth,
int expiryYear = currentYear());double contractValue(std::string name, char expiryMonth, int expiryYear) {
return ...;
}expiryYear.Language
Basic Types
CPP inherited all of the basic fundamental types from C including ints, floats, characters, pointers and more. There're a few amendments and syntactical improvements to the types offered by CPP.
Digit Separators c14
// You can use ' to separate digits for readability like _ in python.
const int num = 1'000'000;Binary Literals c14
No longer will creating bit-flags be so cumbersome: 0b101010.
Functions
Inline Functions
CPP inherits the inline function concept from C++ with some slight amendments for
classes. Any function that is declared AND defined within the class is implicitly
inlined. You can also mark a function defined outside of a class as inline with
the inline keyword.
Lambdas c11
Create small anonymous functions that can capture the state of local variables.
template <class T>
T sum_squares(const std::vector<T> &v) {
T result = 0;
std::for_each(v.begin(), v.end(),
[&result](const T &t) { result += t * t; });
return result;
}The contents of the square brackets determines the list of variables from the local scope that are captured by the lambda, forming a closure with them.
Classes
// ClassName.h
class ClassName {
public:
void method1();
std::string attr1;
private:
void privateMethod;
int attr2;
};
// ClassName.cpp
void ClassName::method1() {
std::cout << "Method 1" << std::endl;
// The pointer this references the current class.
this->privateMethod();
}
void ClassName::privateMethod() {
std::cout << "privateMethod" << std::endl;
// We can access instance variables without this->.
std::cout << "attr1: " << attr1 << std::endl;
std::cout << "attr2: " << attr2 << std::endl;
}RAII
A concept at the heart of C++ and OOP in C++. Essentially the acquisition of resources is the initialisation of an object, and the relinquishing of resources is the destruction of that object.
Constructors
Are functions of a class used to initialise a new object for that class.
Note: Providing a constructor with some arguments prevents C++ from auto-generating a default constructor, meaning default initialisation will no longer work.
Initialising Data Members
Data members for a class are initialised by the constructor. The classic assignment
=form of initialisation within the body of the constructor doesn't give the class a chance to initialise the data members so instead C++ uses an alternative syntax.class Foo { public: Foo(); private: int anInt; std::string aString; }; Foo::Foo() { // Foo.anInt and Foo.aString have already been initialised, // we're simply re-assigning them here. anInt = 5; aString = "Hello"; } // This syntax allows us to initialise the members directly. Foo::Foo() : anInt(5), aString("Hello") {}
Multi Argument Constructors
C++ is unlike java and many other languages in that declaring a variable is sufficient to initialise that variable (see declaration, definition, initialisation and assignment). In case we don't supply an initial value, most types will be default initialised if they have a default constructor.
int foo; // Has a default value, probably garbage. std::string str; // Default constructor called.Even the assignment operator when used alongside a declaration actually results in a constructor call with a single argument of the assigned type.
// The argument here is a cstyle string which the constructor of std::string copies // into heap memory. We're not assigning a cstyle string to the type of std::string, // we're performing a function call with one argument. std::string str = "foo"; // Under the hood c++ actually does something like this. std::string str; str.operator=("foo")To allow multi-argument constructors, the C++ standard introduced a new syntax for initialising variables. It looks semantically equivalent to a function call with all the required arguments.
std::string foo("bar");
Copy Constructor
Is a special constructor that the compiler implicitly calls whenever there's an attempt to initialise an object with an existing instance of the same class as that object.
Foo::Foo(const Foo &target) : d_fooField(target.d_fooField) {}Warn: The constructor takes a reference, and not an instance, because otherwise it would copy the argument parameter leading to infinite recursion.
Copy Assignment Construction
Copy assignment construction is a special application of the assignment operator where we try to initialise a new object by copying in the values of an existing object. It's used to allow a class to cleanup old values and copy in new values into an existing object. Essentially an in-place update operator for a class.
class Foo { public: Foo& operator=(const Foo &foo); // ... }; Foo& Foo::operator=(const Foo &foo) { if (this != &original) { // Copy values from foo into this. } // Must return a reference because return // value should be an lvalue that can be // chained (i = j = k). return *this; } Foo foo; // Default constructor called Foo bar(foo); // Copy constructor called bar = "bar"; // Copy assignment constructor calledNote: To prevent allowing a class to be copied like this, you can declare a private copy-assignment method and avoid providing a definition. This prevents it from being called.
Constructor Delegation
Allows you to call one constructor from another.
class Foo { public: Foo(std::string str) { /* ... */ } Foo() : Foo("default string") {} };
Initializer Lists c11
Are C++11s solution for the most vexing parse problem.
Their are essentially a drop in replacement for the classic parenthesis based constructor call syntax, with some additional extensions to support uniform initialisations for user-defined collections.
std::vector v1; // Default initialised
std::vector v2(); // Default initialised
std::vector v3{}; // Default initialised with empty initialiser list
std::vector v4{1,2,3,4}; // Initialised with initialiser list
The semantics of how initializer lists work are relatively simple. If a class
defines a constructor taking a single argument of type std::initializer_list<T>
then the compiler will construct an initializer_list object and pass it to that
constructor. If the class does not have such a constructor then each argument of
the initializer list is passed as a regular argument to a constructor taking a
matching type using the same lookup rules as a regular constructor call.
Note: The empty initialiser list is an exception. When used the default
constructor for the class is invoked, not the constructor taking an
initializer_list.
Note: Initializer lists only have const access to items in the argument list.
Narrowing Prevention
Initializer lists also prevent implicit narrowing type conversions.
int i0 = 66.6; // OK, but loses precision int i1{66.6}; // Compile-time error: narrowing
Syntax Sugar for Argument Lists
You can use initializer lists as a convenient way to pass a collection of arguments, like you can with variadic parameters.
int addAll(std::initializer_list<int> nums) { int result; for (auto num : nums) { result += num; } return result; } addAll({1,2,3,4,5}); //=> 15
Operators
Are just regular member functions of a class that provide certain features of that class in relation to other classes.
Precedence and Associativity
Table 2: List of available operators in order of precedenceOperator Associativity ::L x++,x--,T(),f(),x[],.,->L ++x,--x,+x,-x,!,~,(T),*x,&x,sizeof,new,deleteR .*,->*L *,/,%L +,-L >>,<<L <,<=,>,>=L &L ^L \(\vert\) L &&L \(\vert\vert\) L ?:,throw,=,+=,-=,*=,/=,%=,>>=,<<=,&=,^=, \(\vert =\)R ,L
TODO Implicit Operator Implementations
Inheritance
// Parent class.
class Animal {
public:
Animal::Animal(int numberOfLegs);
int numberOfLegs() const;
// ...
private:
int d_numberOfLegs;
};
Animal::Animal(int numberOfLegs) : d_numberOfLegs(numberOfLegs) {}
int Animal::numberOfLegs() const { return d_numberOfLegs; }
// Create a derived object.
class Cat : public Animal {
public:
Cat();
private:
int d_numberOfEars();
friend void swap(Cat &a, Cat &b);
};
// Constructor which calls the parent class constructor.
Cat::Cat() : Animal(4), d_numberOfEars(2);
void swap(Cat &a, Cat &b) {
// Call parent class swap function for Animal.
// Note: taking a reference to a parent class doesn't
// perform a conversion, since the fields are packed
// the same in both the base and subtype struct.
swap(static_cast<Animal &>(a), static_cast<Animal &>(b));
std::swap(a.d_numberOfEars, b.d_numberOfEars);
}struct is public and class is private.| Inheritance | Anything that is ? in base class | will become ? in derived class |
|---|---|---|
| Public | public | public |
| Private | public or protected | private |
Finalising Implementations
You can mark a class or a member function as
finaland any later attempt to override or inherit from it will fail.class Foo { public: virtual void bar() final; }; class Bar final : public Foo { // Error, cannot override final member function bar(). // void bar() override {} }; // Error, cannot override final class Bar. // class Baz : public Bar {};Note: Final and override are both only keywords after the parens of a function. Outside of this context you can use them as regular identifiers even for variable names. Don't do this, it's confusing.
See also
-Wsuggest-final-types,-Wsuggest-final-methods, and-Wsuggest-override.
Method Binding
Method binding can be either static or dynamic, defaulting to static. With static binding the method to call is determined by the static type of the object we use to call the function. With dynamic binding we store a pointer to a vtable
vPtrtied to the objects type in the object itself. The compiler builds the vtable (Virtual *Function Table) which keeps a pointer to a method (either overridden in the derived type or pointing to the method in the parent type) for each virtual method in the base type (and all its parent types).Note: The key thing to remember about dynamic binding is that the binding to the method is deferred until runtime.
Cat cat; Animal& animal = cat; // The type of the variable to the left of a function call // determines which function to call, since the function is // bound at compile time. cat.animalMethod(); // Calls implementation in derived Cat animal.animalMethod(); // Calls implementation in base Animal // We can also explicitly call the implementation in a base class. cat.Cat::animalMethod(); cat.Animal::animalMethod();Code Snippet 4: Demonstration of classic static binding.class Animal { public: virtual void sayHello(); // Note: to force implementing classes to provide an implementation // for the virtual function suffix the declaration with ~= 0~. // virtual void sayHello() = 0; }; class Cat { public: // Note: the virtual qualifier here is [[https://stackoverflow.com/a/4895297/6247387][optional]], but recommended // for clarity. // Note: the override keyword simply ensures you're deriving an // existing function, and will fail if some parent type doesn't // define it. // Note: The virtual and override specifiers can only be used // within the body of a class. To implement them they should be // omitted. virtual void sayHello() override; }; Cat cat; Cat &catRef = cat; Animal &animalRef = cat; catRef.sayHello(); // Calls implementation in cat class. animalRef.sayHello(); // Calls implementation in cat class.Code Snippet 5: Demonstation of dynamic binding.Note: Dynamic binding only works with references or pointers.
Note: You should always declare a destructor as virtual, to ensure its binding is dynamic and the correct method is called at runtime. Although this is a good rule of thumb it's not a rule.
Upcasts and Object Slicing
Casts in C++ differ from the ones in Java in that casting a variable to a new
type actually slices the fields of the type. For example casting a Cat to an
Animal creates a new animal instance with only the fields in the base type
copied over. On the other hand if we assign to a reference of the parent type
there's no newly sliced object, instead the reference points to the same object
as the original variable but the function can only access the fields of the
parent type through that reference.
All of this is only possible because classes are structures and the arrangement of fields don't differ between parent and child types.
Cat myCat;
// Safe implicit casts.
Cat& catRef = myCat;
Cat* catPtr = &myCat;
Animal& animalRef = myCat;
Animal* animalPtr = &myCat;
// Object slicing.
Animal animal(cat);
animal = cat;Enumeration Classes
Are an extension of the regular numerical enumerations provided by C. They differ in that enumeration classes don't dump the enumeration entries into the global scope. Instead each enumeration entry is placed in a namespace matching the enum class.
enum Color { e_RED, e_BLUE, e_GOLD };
Color color = e_GOLD; // Can assign from global scope.
enum class CColor { e_RED, e_BLUE, e_GOLD };
CColor color = CColor::e_GOLD;Beyond name-spacing enum classes also allow specifying a base type for the
enumeration (such as a character instead of an integer) and they cannot be
implicitly casted to integers (to do this you must static_cast).
Reference Qualifiers
Allows overriding member functions based on the temporariness of *this.
For example, if you have a class containing a string and a method to return that string you likely don't want to have to copy and return the value of that string if the object containing the string is about to go out of scope. It makes sense to simply move the string outside of the object.
class StringBuilder {
std::string d_str;
public:
std::string get() const & { return d_str; }
// When *this is temporary, move d_str outside of *this.
//
// A new string will be initialised from the R-value of d_str,
// and returned. d_str is essentially cheaply moved out of
// StringBuilder.
std::string get() && { return std::move(d_str); }
};
StringBuilder sb;
// ...
sb.get(); // Calls overload 1, sb still exists past this point.
StringBuilder{}/* ... */.get(); // Calls overload 2, *this is temporary
The way we attach a reference qualifier is by adding const & or && to after the
closing parenthesis of a member function. This isn't limited to just these two.
You can overload based on const, volatile, reference, and R-value.
Note: If you attach a reference qualifier to a member function, you can't have an overload with no ref-qualifier.
Automatically Defined Methods
A C++ class has a rich set of methods given to it for free.
| Method | From Standard |
|---|---|
| Default constructor | C++3 |
| Default destructor | C++3 |
| Copy assignment operator | C++3 |
| Copy constructor | C++3 |
| Move constructor | C++11 |
| Move assignment operator | C++11 |
There are some situations where the compiler will delete these default method definition. For example if you define a custom constructor then the default constructor will be deleted.
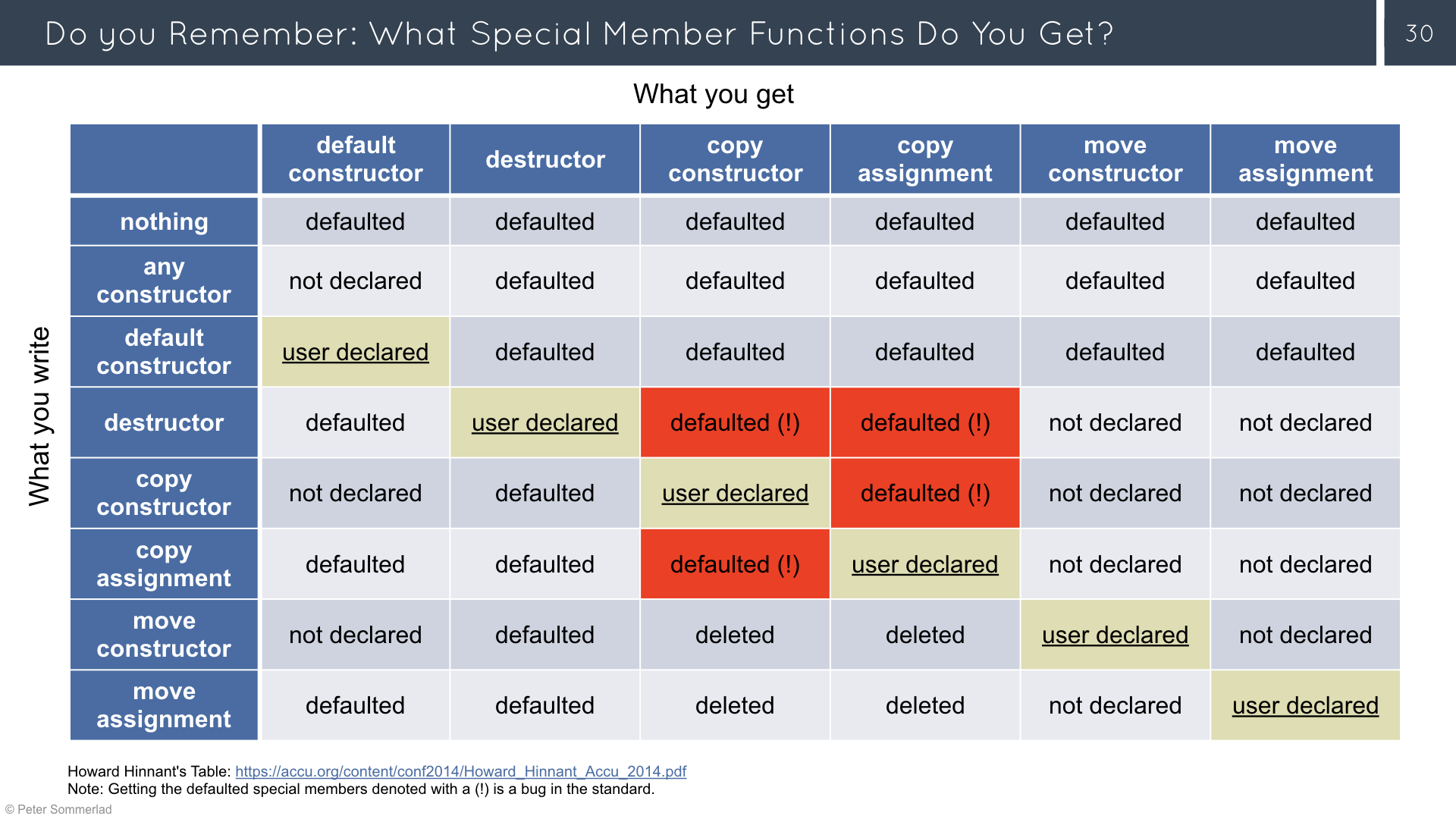{kind=link}
Redefining Implicitly Deleted Member Functions
class Foo { Foo(int n) {} // Defining this caused Foo() to be deleted. Foo() = default; // Re-define the default constructor. };
Delete a Default Member Function
By assigning a member-function prototype to
delete, you prevent that function from ever being called by any code. Deleted function still participate in name lookup so you can use them as a way to avoid certain casting behaviour during initialisation. For example an short could be casted from an int, but you only ever want your class to be instantiated by shorts directly.class Foo { public: Foo(short n); // Allow creating from a short Foo(int n) = delete; // Inhibit constructing from an int. Foo(const Foo& rhs) = delete; // Inhibit copy constructing Foo objects Foo& operator=(const Foo& rhs) = delete; // Inhibit copy-assignment };
Exceptions
CPP introduced an exception mechanism. Any function in a program may throw an exception, at which point the call stack of that function will be unwound until a handler for that exception is reached or it terminates the program.
double getPrice(std::string name, char expMonth, int expYear) {
// ...
if (!isValid(name)) {
throw std::invalid_argument(name + " - Invalid name");
}
// ...
}
void fn() {
try {
double value = contractValue("HG", 'K', 2019);
// ...
} catch (std::invalid_argument &ex) {
// Note: Always catch as a refrence, to avoid object splicing.
// ...
} catch (std::string &ex) {
// A string? You threw a string?
} catch (...) {
throw;
}
}Note: The exception unwind process cleanly cleans up any local variables. Every object on the stack for a stack frame that's unwound has its destructor invoked. Which is then expected to clean up that objects resources. This is why CPP doesn't have a finally clause. Any cleanup logic should be isolated to the object that manages it.
Warn: By convention if another exception is raised while an exception is propagating (such as in a destructor for an object that was just deleted) then the program immediately terminates. This is because otherwise you'd have two exceptions being raised simultaneously and there's no syntactical way to define this.
Exception Guarantees
The guarantees for a function throwing an exception comes in several tiers:
| Tier | Description |
|---|---|
| No-Throw | Can never throw – The gold standard |
| Strong-Exception Safety | If operation fails, no resource leak, no change in state |
| Basic-Exception Safety | If operation fails, no resource leak, possibly a change in state, yet still valid |
| No exception safety | No guarantees |
Idiomatic Safety
To write a truly exception-safe function (one that doesn't corrupt the local state) functions we follow a simply idiom. Essentially we separate the prepare and modification steps. We build up all the data we need that may throw an exception on the stack and then actually perform destructive operations at the end.
void safeOperation(X x, Y y) { // Preparation // Work done on the stack, or ‘to one side’ // Any operation can potentially throw // Any throw abandons the work // The object hasn't been changed // Completion // Free and reassign resources // Nothing can now throw }Copy Constructor example
A classic example would be an assignment operator. We can create a copy of the target object and then, if that succeeds, swap each field between the original object and the copied object.
Note: Observe how elegantly this approach would handle destructuring our original objects state. When we create the copy, the copy acquires any resources our new object will need. We then copy any old resources we won't need into our copy, also copying the new resources we will need back into our original object, and then finally we destroy the copy effectively releasing the unnecessary resources all at once in a way that safely maintains the state of the object that the assignment returns.
Foo& operator=(const Foo &other) { // Preparation Foo copy(other); // Completion std::swap(d_field1, copy.field1); std::swap(d_field2, copy.field2); return *this; }// In foo.h class Foo { private: int fooA; std::string fooB; // Let swap access private members friend void swap(Foo &a, Foo &b); }; void swap(Foo &a, Foo &b); // In foo.cpp Foo &operator=(Foo other) { // We pass other by value so the compiler allocates it // on the stack for us. swap(other, *this); return *this; } void swap(Foo &a, Foo &b) { std::swap(a.fooA, b.fooA); std::swap(a.fooB, b.fooB); }Code Snippet 6: Copy swap, where preparation is handled in the stack.
Destructor No-Throw
The destructor for an object should have strong no-throw guarantees.
This is because an objects destructor is always called when it's cleaned up. If a function throws an exception, the stack frame is unwound and any local objects destructors are called to clean them up, and if the destructor now throws an exception then the program has two exceptions thrown at the same stack level and it terminates (this cannot be handled).
Access Specifiers
friend
Allows classes to expose private internal data-members to certain functions or classes.
class Foo {
private:
int bar;
friend void useFoo(Foo &foo);
};
void useFoo(Foo &foo) {
// useFoo can access private members of Foo,
// because it's a friend.
std::cout << foo.bar << std::endl;
}The friend relationship is not transitive. You can friend another class meaning all member functions of that class can access private fields from your class, but if that class friends another class you can't transitively access the original classes private fields through the friended class.
const
Marks a variable or return value or operation as non-modifiable.
Note a function can be marked unique based solely on the value of const. This may
surprise you, but recall member functions work by having an implicit pointer to
that class (called this) as its first argument. Marking a function as const
changes the signature of the function to take a const ClassName *this instead,
which is a different type.
Note: Constant variables must be initialised, otherwise there's no way to later give them a value.
A trailing constant on a member function means this function doesn't modify the class object it's called for.
class Foo {
double foo;
public:
double real() const { return foo; }
}Visibility Specifiers
publicAccessible both within and outside of the object.
protectedAccessible only by the object and derived types.
privateAccessible only by the current type, not derived types.
Memory Management
Storage Duration
| Type | Duration | Location | Description |
|---|---|---|---|
| auto variable | auto | stack | Initialisation -> End of code block |
| temporary | auto | stack | Initialisation -> End of full expression |
| parameter | auto | stack | Function call -> Function exit |
| static (local) | static | data-segment | Initialisation -> Program exit |
| instance | object | object | Object |
| static (class) | static | data-segment | Program start -> Program exit |
| global | static | data-segment | Program start -> Program exit |
| dynamic | dynamic | heap | When I want -> When I want |
Note: A local static variable is initialised the first time that local variable is required (often when the enclosing function is called). This is because the variable may behave differently when called at runtime compared to program startup. Use this when you want to avoid repeatedly allocating (and deallocating) something you intend to reuse.
Dynamic Memory Allocation
The
newoperator lets us request data from the heap (to instantiate an object), returning a pointer to the new memory, and thedeleteoperator calls the deconstructor of an object and then frees the memory allocated for it.X *x1 = new X("aaa"); x1->f(); X *x2 = new X(*x1); X *x3 = new X(); *x3 = *x2; delete x3; delete x2; delete x1;There's a similar syntax for dynamically allocating memory for an array.
// Initialises 10 ints, calling the default constructor for all of them. int *ints = new int[10]; delete[] ints; // Can also initialise values like C. int *ints2 = new int[5] {1, 2, 3, 4}; // 1, 2, 3, 4, 5, 0Placement New
Allows you to allocate into an existing object reference. Ordinarily
newcreates memory and calls the constructor. Placement new calls the constructor, but doesn't need to allocate the memory because the memory is passed to it.// In this the constructor for X is called twice. X x; X* p = new (&x) X; // The addresses are the same because the object was // initialised in already allocated memory. &x == p;If you pass an allocator in place of the address,
newwill use the allocator to allocate memory and you can later free it using the allocator as well.MyAllocator allocator; std::string foo = new (allocator) std::string("Foo", allocator); allocator.deleteObject(foo);
L-values and R-values
L-values are values that can appear on the left or right hand side of an =
operator. An R-value is a value that can only appear on the right hand side
of an = operator.
int x = 100;
// A reference is an L-value and can appear on both the left and
// right hand side of an expression.
int& fn() {
return x;
}
void usesfn() {
int a = fn();
a = 200; // x = 100
int& b = fn();
b = 200; // x = 200
fn() = 300; // x = 300
}Note: L-values and R-values can both be bound to constant L-value references.
void foo(int&); // (1)
void foo(const int&); // (2)
int a = 5;
const int b = 10;
foo(a); // Calls (1)
foo(500); // Calls (2)
foo(b); // Calls (2)
Pointers
A pointer is a value that addresses some memory. The semantics of pointers in CPP are identical to C.
Null Pointers
Is a pointer type that does not in-fact point anywhere. Earlier versions of c++ used to implicitly cast 0 to the null pointer, but the need for a strongly typed null pointer value eventually lead to the creation of
nullptrandnullptr_t.void foo1(Bar *bar); foo1(nullptr); // When you have a function accepting multiple pointer types, // nullptr_t is required to be able to handle the nullptr type. void foo2(char *bar); void foo2(double *bar); void foo2(std::nullptr_t bar); foo2(nullptr); foo2((char*)nullptr); // However you can also just manually cast the type here.
Managed Pointer Types
Are special pointer types that acquire a resource newly allocated on the heap and automatically free that resource when the pointer goes out of scope.
template <class T> class SmartPointer { private: T *myPtr; public: SmartPointer(T *arg = 0) : myPtr(arg) {} ~SmartPointer() { delete myPtr; } T *operator->() const { return myPtr; } T &operator*() const { return *myPtr; } }; void foo(){ SmartPointer ptr(new Foo()); // ptr takes ownership of newly allocated heap object ptr->doFoo(); // Can use just like a regular pointer type for Foo // When ptr goes out of scope the destructor for it will be called and automatically // free the allocated memory. }Code Snippet 8: Demonstration of a safe pointer wrapper type.Unique Pointer
A unique pointer is a single pointer type which takes unique ownership of an object.
#include <memory> std::unique_ptr<Foo> ptr1(new Foo()); ptr1->someMethod(); // Call method on Foo through the pointer type. ptr1.get(); // Gives access to the raw pointer (for use with legacy libraries). // You can't copy a unique pointer but you can transfer/steal ownership into a // new pointer. std::unique_ptr<Foo> ptr2(std::move(ptr1)); ptr2.reset(new Foo()); // Release the old resource and assign a new resource. // This will call delete on the original object because // there's no open pointers to it left. ptr2.reset(); // Reset to point to the null pointer (make it empty). ptr2.release(); // Stop managing pointer, owner must explicitly delete // it themselves.Note:
unique_pointeraccurately handles the situation where we've allocated an array instead of a single object (callsdelete[]in its destructor).
Shared Pointer and Weak Pointers
Shared pointers are a pointer that can be shared by multiple other shared pointers and only frees the resource when no shared pointer to it remains. It does this by maintaining a reference count. Every copy operation increases the count and every destructuring operation decreases the count. Shared pointers also accept a destroyer parameter that's used to free the pointer.
We refer to the memory block where the shared pointer stores both weak and strong reference counts as the control block. The control block is also where the destroyer for the resource will be stored.
All shared pointers pointing to the same value reuse the same control block. The control block will likely have to be allocated dynamically. To avoid repeat allocations for creating a shared pointer. The standard defines a helper which will allocate both simultaneously.
std::shared_ptr<X> x1(std::make_shared<X>("a"));Note: A shared pointer supports all the same operations as a unique pointer including some more:
std::shared_ptr<X> x1(new X("a")); x1.use_count(); //=> 1 // Strong reference count to object X("a") std::shared_ptr<X> x2(x1); // Initialise from existing shared pointer std::shared_ptr<X> x3 = x2; // Supports assignment initialisation x1.use_count(); //=> 3 // When the shared pointer is deleted the reference count drops. { std::shared_ptr<X> x4(x3); x1.use_count(); //=> 4 } x1.use_count(); //=> 3Note: Shared pointers and weak pointers are designed to be used in thread safe code so all copy and deconstructing operations are atomic. This introduces a notable slowness when passing them by value, so the convention is to pass such pointers by reference (
constor otherwise).Weak References
A weak pointer is a pointer to the same data owned by a shared pointer, except it maintains a different weak reference count. A resource is destroyed once it's strong reference count drops to 0, and a control block is destroyed once its strong and weak reference count is dropped to 0.
This is to avoid the situation where two objects may have a cyclic reference to each other causing them to keep each other alive even when there's no shared pointer to them anymore; meaning there's no route to them for any code path, but because they point to each other, their reference count never drops and their never destroyed. Consider two objects:
AandB.Ahas a strong reference toB(as a data member) andBhas a weak reference toA. Also there's one shared pointer with a strong reference toA.Table 7: Demonstration of the state of the weak reference example above.Object Weak Reference Count Strong Reference Count A 1 1 B 0 1 What happens when the shared pointer to
Ais freed?- The strong reference count for
Adrops to 0, so the resource forAis freed but the control block is not because there's still a weak reference to it. - On free the strong reference from
A -> Bis freed so the strong reference count forBdrops to 0. Because both the strong and weak reference count forBare now 0 the resource and control block forBare freed. - The weak pointer from
B -> Ais freed so the weak reference count forAdrops to 0 and the control block for it is freed.
Warn: A weak pointer doesn't prevent the pointed to object from being cleaned up. Furthermore you cannot use a
weak_ptrlike a regular pointer type, because this would cause a race condition. If you need access to the pointed to value you must explicitly receive ashared_ptrto it (ornullif it's been deleted). This can be done with thelockmethod.std::shared_ptr<X> sp1(new X); std::weak_ptr<X> wp1(sp1); // Created from an existing shared pointer wp1.expired(); //=> true // Does the pointed to value still exist? wp1.use_count(); //=> 1 // Number of weak references to object X() std::weak_ptr<X> wp2(wp1); // Created from an existing weak_ptr wp1.use_count(); //=> 2 // lock() obtains the pointee // It may return 0 wp1.lock()->m(); // Obtain and call a method on a shared pointer // Warn: May throw an error because pointer is null sp1.reset(); // Explicitly release this shared pointer wp1.expired(); //=> true // No strong references left so object was deleted if (std::shared_ptr<X> = sp1.lock()) { // Truthy if the shared pointer was correctly acquired }Warn: You cannot cast a weak pointer to a bool, like you can a shared pointer.
- The strong reference count for
References
A reference is like a pointer, except it must be initialised to some value and it cannot be made to reference some other memory address.
It may help to think of references as aliases to another variable. Modifying the reference modifies the aliased value.
void swap(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
int a = 1;
int b = 2;
swap(a, b); // Implicitly made into a reference
Ideally you should always pass user defined types as references (because this avoid any move logic resulting in function calls that may throw errors). Builtin primitives such as double, int, etc. should be passed by value. References for these types have an implicit overhead whenever their accessed (pointer dereferencing) and it may take up more memory than the argument itself (bytes = 4 bytes = 32 bits, on 64-bit machines pointers take up twice that size).
R-value References & Move Constructors
R-value references provide a way to directly address R-values and avoid the need for implicit copying by the compiler. Instead we can now allow classes to cheaply take ownership of data and state stored in an object about to be freed.
A common application of this would be a move constructor: A constructor taking a mutable R-value reference to an existing object of the same class. The move constructor will move (take ownership) of data stored in that class from the R-value and place dummy data in the R-value so when its freed the data is persisted in our new object. Take for example a temporary vector initialised and returned from a function by value and used to initialise a new vector in the caller function.
std::vector<int> getVec(); void foo() { std::vector<int> myVec = getVec(); }The move constructor can cheaply take ownership of the existing vectors (returned from
getVec()) buffer, and gives it anullptrbuffer, so when the R-value is cleaned up the contents of the vector is persisted inmyVec.template <typename T> std::vector<T>(const std::vector &rhs) : d_size{rhs.d_size}, d_buffer{new T[rhs.d_size]} { // Copy values from rhs to initialise a new vector. } std::vector<T>(std::vector &&rhs) : d_size{rhs.d_size}, d_buffer{rhs.d_buffer} { // When rhs is finally cleaned up, it'll have no data it // needs to free. rhs.d_buffer = nullptr; }Code Snippet 9: Skeleton implementation of a copy constructor and move constructor.Note: A move constructor is not added by default to any class that has a non-default constructor.
Note: What state the object will be in post-move for the default move-constructor isn't well defined. You should assume you'll never be able to use an object after a move.
Forcing Transference of Ownership with
std::moveIn some situations you may want to force a transference of ownership from one object to another. This can be done by casting the right hand side of an assignment/initialisation from a L-value to an R-value which the
std::movehelper function can do.std::vector<int> src; std::vector<int> dst = std::static_cast<std::vector<int>&&>(src); // dst stole ownership of data in src, src is now no-longer valid. // A slightly cleaner way to do this would be to use std::move, which // triggers this conversion to an R-value for us. std::vector<int> dst = std::move(src);Note:
std::move(src)isn't doing any sort of modification onsrc. It's doing compile time manipulations to cast the value from an L-value to an R-value. Passing the R-value tostd::vector<int>::operator=(std::vector<int> &&rhs)is what's actually transferring the ownership of data.Explicitly marking an L-value as an R-value can be dangerous. If you don't properly remove any state in the
srcthat's now stored in thedstor if you keep usingsrcwhen it's no longer considered valid. Consider the following example:struct Foo { int *a; Foo() : a{new int{5}} {} // Take ownership of a stored by RHS. Foo(Foo&& rhs) : a{std::move(rhs.a)} {} // Release the resources we're holding onto ~Foo() { if (a != nullptr) { delete a; } } }; int main() { Foo x{}; std::cout << (void *)x.a << '\n'; //=> 0x1933010 { Foo y{std::move(x)}; std::cout << (void *)x.a << '\n'; //=> 0x1933010 std::cout << (void *)y.a << '\n'; //=> 0x1933010 // y.a is deleted here, and its the same as x.a } // x.a still points to the same address as y.a std::cout << (void *)x.a << '\n'; //=> 0x1933010 } // x.a is deleted once again leading to a double free error.The
Fooobject has a move constructor that takes ownership of a pointer stored in the class, but it doesn't swap out the pointer that it's taken ownership of causing a later double free error. When managing resources like this you should make sure the R-value is in a state such that freeing it won't corrupt the newly constructedFooobject. For convenience thestd::exchangehelper lets us move ownership of a field from an existing class and assign it to a new value at the same time.Foo::Foo(Foo&& rhs) : a{std::exchange(rhs.a, nullptr)} {}Note: Try not to confuse exchange and swap. Swap only accepts L-values for both left and right hand sides. Exchange uses perfect forwarding and can swap the value with both an L-value or an R-value. It also returns an R-value reference to the original value so you can assign from it. Swap returns nothing.
Type Conversions
C++ supports both explicit and implicit conversions for both built in and user
defined types.
An implicit conversion is one that occurs without the user having to write any
code to make it happen. An example could be casting a numerical type to another
numerical type with a greater range (a short -> long, or unsigned int -> unsigned
long). In these cases the value of the original variable is not lost, because
we're casting to a type that can represent more values. In actuality C++ is much
more liberal than just this sort of implicit conversion.
An
Note: An enum can implicitly be converted to any integer types larger than or
equal to an int (and optionally unsigned) so long as the destination type is large
enough to hold all of the enumerator values.
Note: A char is the smallest integral type and can be implicitly converted to any
other numeric type including floating point ones.
Note: A bool can be converted to and from any numerical type (a 0 value is false,
and a 1 value is true). You can also convert pointer types to bools, with the bool
being false if the pointer is equal to the nullptr.
Implicit Casts
If a class has a constructor taking only a single argument, you can implicitly convert to an instance of that type to an instance of the class.
class Foo {
public:
Foo(const std::string str);
};
void useFoo(Foo foo);
void useFooRef(Foo &foo);
void useFooRefConst(const Foo &foo);
std::string myStr = "Hello world";
Foo myFoo = myStr; // Implicitly converted
// Demonstration of implicit conversion in practice.
useFoo(myFoo); // Copied, but no conversion needed.
useFoo(myStr); // Converted std::string → Foo and then copy.
useFooRef(myFoo); // Pass by reference, no conversion and no copy.
useFooRef(myStr); // *error*: no conversion to modifiable L-value.
useFooRefConst(myFoo); // No copy, trivial conversion (since myFoo is
// modifiable, and useFooRefConst wants a read
// only reference to it).
useFooRefConst(myStr); // Conversion std::string → Foo and reference to const
Note: You may wonder why useFooRef(myStr) throws an error whereas
useFooRefConst(myStr) does not, in code:imp-conv-udt.
This is because in the former case the compiler needs to convert myStr into a Foo
and it does this by creating a temporary object. The temporary object is an
R-value, we can't guarantee that it's location can be determined AND is
modifiable, meaning we can't pass it as a mutable reference to useFooRef.
However in the latter case we only need a constant reference, which can be
received through an implicit conversion.
Note: As for why you can only have constant references to temporary variables, it's because if they're mutable the function would be indicating it wants to modify that object and modifying an object that will be disposed of almost immediately is meaningless (and likely an error).
std::string foo("BBG00F0S24M9");
Foo fg(chars); // No Conversion (Direct Initialization)
Foo fg2 = chars; // Implicit Conversion (Copy Initialization)
fg = chars; // Implicit Conversion
Note: If you don't want to allow implicit casts for a user defined type, you must mark the constructor as for explicit casts only.
class Foo {
public:
explicit Foo(const std::string &str);
};Explicit Casts
C++ inherited the classic (type)obj explicit casting style from C and also
introduced a new function-call type(obj) style and a myriad of compile time
and runtime casting functions.
| Helper | Example | Properties | Description |
|---|---|---|---|
| static cast | static_cast<NewType>(obj); | Fast, cannot weaken const/volatile-qualifiers | Performs implicit or explicit conversions smartly |
| constant cast | const_cast<SameType>(obj); | Fast, compile-time, cannot change type | Remove const/volatile qualifiers from a type (avoid!) |
| dynamic cast | dynamic_cast<*NewType>(ptr); | Run time type cast, null if invalid cast | Cast pointers between polymorphic (class) types |
| reinterpret cast | reinterpret_cast<NewType>(obj); | The dark arts, probably best not to, eh? | Cast from anything to anything (Never Use!!!) |
Note: static_cast only checks whether there's a route from the type of obj to
NewType. This could be both up and down the inheritance hierarchy. dynamic_cast
allows casts between types (throwing a std::bad_cast if the cast is an invalid
reference cast (since references must be initialised)).
class Baz; // Derives from Foo, Bar
Baz baz;
Foo* foo_p = &cf;
Bar* bar_p = &cf;
// Allowed but dangerous. if pointer doesn't point to a Baz type
// you may end up with a Baz* to something that isn't a Pointer.
ASSERT_EQ(&cf, static_cast<Baz*>(s_p));
ASSERT_EQ(&cf, static_cast<Baz*>(j_p));
// Dynamic casts are a generally safer alternative. Will return a
// nullptr if the cast fails.
ASSERT_EQ(&cf, dynamic_cast<Baz*>(s_p));
ASSERT_EQ(&cf, dynamic_cast<Baz*>(j_p));
// Can also side cast to sibling parent types.
ASSERT_EQ(s_p, dynamic_cast<Foo*>(j_p));
ASSERT_EQ(j_p, dynamic_cast<Bar*>(s_p));Note: C-style and functional casts described above actually run the explicit cast functions (see tbl:expl-cast-generic) in the following order:
const_caststatic_cast(though ignoring access restrictions)static_cast(see above), thenconst_castreinterpret_castreinterpret_cast, thenconst_cast
User Defined Cast Functions
You can create an operator for your classes that C++ will use when there's an attempt to cast objects of your type to another type.
class Foo {
public:
Foo(const std::string &chars);
operator const std::string &() const;
};
// Cast function for Foo → std::string
// Note this cannot be made explicit in C++03
Foo::operator const std::string &() const { return "Foo"; }
// Application of both implicit and explicit casts.
Foo foo("Hello Friend");
const std::string& s1 = foo;
const std::string& s2 = static_cast<const std::string&>(foo);Namespaces
Allow grouping names within a namespace to avoid name collisions.
// In bar.h
namespace Foo {
class Bar {
public:
void bar();
// Classes also count as namespaces, meaning you can
// define a class within a class. Note: nested types
// have access to private members of the enclosing
// class.
class Baz {
void baz();
};
// Baz is in the current namespace so we can qualify
// it directly.
Baz &baz;
};
} // namespace Foo
// In bar.cpp
namespace Foo {
void Bar::bar() { std::cout << "In bar" << std::endl; }
// The :: (namespace) operator lets us access namespace members.
void Bar::Baz::baz() { std::cout << "In baz" << std::endl; }
} // namespace Foo
namespace Foo {
namespace Bar {
void Baz::fn() { std::cout << x << std::endl; }
} // namespace Bar
} // namespace Foo
Observe the code in code:unq-look. Where is x defined? In CPP the compiler
looks in the current namespace, then the parent namespace, etc., etc., until it
finds the desired identifier. This applies even for partially qualified variables
such as X::Y::Z. To qualify a name (from the global namespace) prefix it with ::,
for example ::Foo::Bar::Baz.
There's also special logic for class data-members. If the data member x is
inherited from a base class then the compiler looks for a definition in each parent
class in the order of inheritance (in case of multiple inheritance) until a valid
name is found.
Note: Overloading is still isolated by namespace scope. For example consider
code:inh-scope. Which function will be called by Derived d; d.fn(5);?
The answer is the implementation in derived. The compiler when choosing a function
works from the current classes scope upwards. If a definition is found in the
current class, the parent class isn't checked (even if it may have a better best
function for our argument types).
Essentially each subclass introduces a sub-namespace with a higher precedence then
the parent scope. This can be fixed by using the definitions from the base-class as
shown in code:inh-scope.
class Base {
public:
std::string fn(int);
std::string fn(double);
};
class Derived : public Base {
public:
std::string fn(float);
// We can fix this by reimporting the ~fn~ name from the
// base class.
// using Base::fn;
};Using
// anothername is an alias for trncpp in this scope.
namespace anothername = trncpp;
anothername::foo == trncpp::foo;The using keyword allows us to import a value or sub-namespace from a namespace into the current scope.
using Foo::Bar;
Bar &bar1;
Foo::Bar &bar2;
// We can also import all the entries in a namespace.
using namespace Foo;Note: the using statement isn't a classical import statement. It doesn't copy definitions from an outer scope into a local scope, instead it exposes values from a given namespace into the tightest scope shared by the current scope and the target scope. This is most clearly demonstrated by code:using-namespace.
X a;
namespace N1 {
X c;
namespace N2 {
namespace N3 {
X a, b, c;
}
}
namespace N4 {
X a;
void locationTest() {
// Imports a, b, c into the shared namespace N1,
// for the duration of the current scope.
using namespace N2::N3;
a; // From N4
b; // From N3
// c; // Ambiguous, conflicts with definition in N1 and N2::N3.
}
}
}Using For Type Aliases
usingwithin a namespace exposes a variable from that namespace.namespace foo { class Foo; } namespace bar { using foo::Foo; } bar::Foo bar; // Can access class in foo namespace from bar.Note: This introduces a slight dilemma. If you want to use
usingto shorten the definition of a type, you expose that type through that namespace. This would be fine in a.cppfile which is compiled in a single text-unit, but in a header file that definition would be exposed in every file that includes it. So avoidusingunless absolutely necessary, and definitely do not use it in a.hfile.
Unnamed Namespaces
Are an alternative to the static modifier from C. Names declared within an
anonymous namespace are injected into the containing namespace but in a way
that is not exposed outside of the current translation unit. Such namespaces
differ from static in that they have external linkage and a few other CPP specific
advantages. At compile time the compiler will generate unique names for each
identifier.
Names in the unnamed namespace are available in the containing namespace for that translation unit only.
// in foo.h
void printBar();
// in foo.cpp
#include <iostream>
namespace {
int printFoo() {
std::cout << "Hello world" << std::endl;
}
}
void printBar() {
printFoo();
}
// in main.cpp
#include <foo.h>
printFoo(); // error: ‘printFoo’ was not declared in this scope
printBar(); //=> Hello world
Argument Dependent Lookup
Is an aspect of CPP where the compiler will first look in the namespace of each of
a function calls argument types for an definition of the function. It does this
after failing to find a definition within the current functions scope/body (can be
given with a using statement), but before it does an unqualified lookup in the
namespace of the current function itself.
#include <iostream>
namespace foo {
class Foo {};
void swap(Foo foo, Foo other) {
std::cout << "Swap in foo" << std::endl;
}
}
int main(){
foo::Foo foo1, foo2;
// Finds definition in foo namespace because
// first argument type is in that namespace.
swap(foo1, foo2); //=> Swap in foo
}Templates
Are a way for CPP to define things in a generic way.
Templates are, by there namesake, a template of an algorithm or class that is instantiated in each translation unit, the first time the argument types are known, into a specialised implementation. The compiler then checks the sanity of the code (for example a parameter of a generic type might use a certain operator in the function, but that's not defined). Once the program is linked the redundant duplicate definitions are removed and only a single implementation is left.
template<class T>
bool allDiffer(T a, T b, T c) {
return !(a == b || b == c || a == c);
}
allDiffer<>(1, 2, 3); // With type deduction.
// bool allDiffer(int a, int b, int c) {
// return !(a == b || b == c || a == c);
// }
allDiffer<double>(1.0, 2.0, 3.0);
// bool allDiffer(double a, double b, double c) {
// return !(a == b || b == c || a == c);
// }
Note: Until C++17 type parameters cannot be deduced. You can't pass a List<int>
to something expecting a List<double>, even though we can cast an int to double
without any loss of information.
Warn: Because a template isn't a definition, just a prototype used to instantiate a real function, it's definition must be available at compile time for any function that needs it. Because of this any template implementations must be placed in header files instead of CPP files.
Type Deduction
Inclusion of angle brackets is what determines whether an argument is looked for as a template or a concrete implementation. Omitting the brackets makes the compiler look for both template and non-template definitions (with preference going for the non-template).
template<class T>
bool allDiffer<T>(T a, T b, T c) {
return !(a == b || b == c || a == c);
}
// A specialisation for integers.
template<>
bool allDiffer<int>(int a, int b, int c) {
return false; // never true when type = double.
}
allDiffer(1, 2, 3); // Concrete implementation => allDiffer<int> => false
allDiffer(1.0, 2.0, 3.0); // Template instantiatied => allDiffer<double> => true
allDiffer(1, 2.5, 3); // error: failed to resolve target function
template <class T> class Foo {
public:
Foo(T value) : d_value(value) {}
// We can omit the template paramter T from Foo<T>
// because within the scope of the class T is already
// intantiated.
T addTo(const Foo &myFoo);
private:
T d_value;
};
// Same story here Foo<T> introduce T to the parameter namespace.
template<class T>
T Foo<T>::addTo(const Foo &myFoo) { return d_value + myFoo.d_value; }
Foo<int> foo(5), bar(5);
foo.addTo(bar); //=> 10
SFINAE
A standard idiom regarding template substitution for C++, if a given type cannot be substituted into a template definition, then that is not an error. Only when there's no overload of a template type that satisfies the provided type do we treat it as an error. The goal here being: if we can arrange for invalid code to be generated, we can control which overload the compiler picks.
This is often used with std::enable_if to restrict certain overloads based on template resolution.
Class Templates
We can also create class templates.
The template variable T is accessible anywhere in the definition of the class.
template <class T> class LinkedList {
public:
LinkedList(const T &item, LinkedList<T> *previous, LinkedList<T> *next);
T &item();
const T &item() const;
LinkedList<T> *previous() const;
LinkedList<T> *next() const;
private:
T d_item;
LinkedList<T> *d_previous;
LinkedList<T> *d_next;
};
// Example generic constructor implementation.
template <class T>
LinkedList(const T &item, LinkedList<T> *previous, LinkedList<T> *next)
: d_item(item), d_previous(previous), d_next(next) {}Note: The CPP compiler only instantiates a template member-function if it is
used, not when a generic type is declared. For example consider
code:temp-inst-type-err. If we never call foo2.timesByFive then the
program will compile fine, but if we do then an error will be thrown. If a
template function isn't called by the program, then it isn't needed and won't be
implemented.
template <class T>
class Foo {
public:
Foo(const T &t);
// Expects T to be an integer type.
int timesByFive() { return t * 5; }
private:
T d_myT;
};
template <class T>
Foo<T>::Foo(const T &t)
: d_myT(t) {}
Foo<int> foo1(5);
foo1.timesByFive(); // Okay, int * 5 is valid.
Foo<std::string> foo1("hello");
foo2.timesByFive(); // Compiler error, cannot times string by 5.
Typed and Non-Typed Parameters
Templates can accept an arbitrary number of template arguments and even non-type parameters. Non-type parameters are literal values which the template can be given at compile time; offering a chance at early optimisation.
The very clear downside to this sort of approach is that every function call to the template with differing non-typed arguments leads to more code generation.
template <class T>
T accumulate(const LinkedList<T> &data, size_t n) {
T result = T();
int count = 0;
const LinkedList<T> *pos = &data;
while (pos && count++ < n) {
result += pos->item();
pos = pos->next();
}
return result;
}template <size_t N, class T>
T accumulate(const LinkedList<T> &data) {
T result = T();
int count = 0;
const LinkedList<T> *pos = &data;
while (pos && count++ < N) {
result += pos->item();
pos = pos->next();
}
return result;
}LinkedList<int> nodeA(5, 0, 0);
LinkedList<int> nodeB(6, &nodeA, 0);
LinkedList<int> nodeC(7, &nodeB, 0);
// Using a regular parameter, and only a single template
// parameter T. Here the template is instantiated once,
// for the first call and then reused for the subsequent
// 4 calls.
ASSERT_EQ(0, accumulate(nodeA, 0));
ASSERT_EQ(5, accumulate(nodeA, 1));
ASSERT_EQ(11, accumulate(nodeA, 2));
ASSERT_EQ(18, accumulate(nodeA, 3));
// Using a non-type parameter.
// Here each call instantiates a new template leading to
// even more code generation.
ASSERT_EQ(0, accumulate<0>(nodeA));
ASSERT_EQ(5, accumulate<1>(nodeA));
ASSERT_EQ(11, accumulate<2>(nodeA));
ASSERT_EQ(18, accumulate<3>(nodeA));
// Observe how both template definitions can exist side-by-side.
// If we supply the parameters in the right way, the right one
// will be resolved and the code will have the intended effect.
Default Parameters
Template parameters, just like regular parameters, can be assigned a default value/type, allowing the caller to omit specifying it.
template <int N, class T, class A = T>
A accumulate(const LinkedList<T> &data) {
A result = A();
int count = 0;
const LinkedList<T> *pos = &data;
while (pos && count++ < N) {
result += static_cast<A>(pos->item());
pos = pos->next();
}
return result;
}
LinkedList<double> nodeA(5.7, 0, 0);
LinkedList<double> nodeB(6.7, &nodeA, 0);
LinkedList<double> nodeC(7.6, &nodeB, 0);
int a1 = accumulate<3, double, int>(nodeA); // T is double, A is int
double a2 = accumulate<3>(nodeA); // T is deduced as double, A defaults to T
T but can be manually overriden.Template Templates
Is the idea of passing a template parameter which may also be template parameterised in terms of one or more other types.
// S is a template taking a single template parameter which isn't
// named when declared because it has no bearing on type deduction.
template <int N, class T, template <class> class S, class A = T>
// template <int N, class T, template <class X> class S<X>, class A = T>
A accumulate(const S<T> &data) {
A result = A();
int count = 0;
const S<T> *pos = &data;
while (pos && count++ < N) {
result += static_cast<A>(pos->item());
pos = pos->next();
}
return result;
}The form shown in code:temp-temp is usable, but requires some very ugly
template instantiations: accumulate<3, LinkedList<int>, <int>>(...). The code in
code:temp-temp-ns shows an alternative approach which is the more
standard approach in C++03. It works by saving the template parameter T in the
namespace of the template class S so it's accessible at compile time. This is
used for example to reference the key and value types in std::map.
template<class T>
class Foo {
public:
typedef T foo_type; // Make the type accessible in the class namespace.
// ...
};
template <int N, class T, class S, class A = T>
typename S::foo_type accumulate(const S &data) {
// Use typename to access the type within the namespace.
typedef typename S::foo_type A;
A result = A();
int count = 0;
const S<T> *pos = &data;
while (pos && count++ < N) {
result += static_cast<A>(pos->item());
pos = pos->next();
}
return result;
}Template Specialisation
Is a form of template overloading where you can define the same template more than once, but provide specific types for the template type parameters. In this case when a developer tries to instantiate a template with the specialised types the specialisation class is invoked instead of the original template class.
Note: A specialised template has no relation to its original type beyond an identifier. It can have a different size, members, functions, etc.
template <class T, class U, class V>
class Foo {
public:
T a_t;
U a_u;
V a_v;
};
// A specialisation of the Foo class.
// You can tell beause the class name Foo is followed by <>.
template <>
class Foo<bool, bool, bool> {
public:
bool b_t;
bool b_u;
bool b_v;
};
Foo<int,bool,float> generic;
Foo<bool,bool,bool> special;
generic.a_t;
generic.b_t; // error: Foo<int,bool,float> has no member b_t
special.a_t; // error: Foo<bool,bool,bool> has no mebmer a_t
special.b_t;Note: We refer to Full Specialisation as when we specialise all the template
parameters of a type leaving template<> before the declaration.
Type Traits
Are a way to expose metadata related to a type, including user-defined types, using specialisation. This allows user-defined types to be substituted into generic functions that call these traits.
template <class T>
bool isMax(const T& t) {
return t == std::numeric_limits<T>::max();
}Take for example code:trait-user. If we create a user-defined number type
(example BigInt) then we can add an overload for std::numeric_limits<BigInt> and
then the existing isMax<T> algorithm will work with our user defined type.
enum Move { e_LEFT, e_RIGHT };
template <class T>
struct DefaultDirectionFor {
// The default direction for any type T
static const Move direction = e_LEFT;
};
template <>
struct DefaultDirectionFor<Cat> {
// Cats move to the right, not the left silly.
static const Move direction = e_RIGHT;
};
// Can check at compile time which direction we want
// for a given template type.
template<class T>
void doMove(T& obj) {
switch (DefaultDirectionFor<T>::direction) {
// ...
}
}Forwarding References
A forwarding-reference is a reference type in template types that captures all
the details of a type T including CV-qualifiers and L-value or R-value semantics.
These are useful for template functions which take either a const T& or a T&& and
have essentially the same body. Instead of creating \( \mathcal{O}(n^2) \)
overloads you can just write a single template function.
Within the context of a template function taking a forward reference, the parameter for the forward reference remembers the argument may be an R-value but in regular usage it's treated as a L-value (because it has a name). To propagate the argument to other functions taking R-values you must forward the L-value parameter as a R-value.
#include <utility>
template<typename T>
void setName(T&& name) {
// std::forward creates a copy of the argument if it's an L-value and
// moves ownership of the argument if its an R-value. Otherwise it's
// treated as if it's an L-value.
d_name = std::forward<T>(name);
}
// Equivalent to independently defining the following, all with basically
// the same body. Notice how this would grow as the number of argument types
// also grows.
// void setName(const std::string& name);
// void setName(std::string&& name);
setName("foo"); // Calls an R-value overload of setName
std::string str{"bar"};
setName("bar"); // Calls an L-value overload of setName
T&& if a forwarding reference, not a R-value of type T. code:perf-forwardstd::forward. These allow perfect forwarding to work. These rules apply because you cannot have a reference to a reference, therefore we collapse such references to regular reference types.What you want foo(?) | What you pass std::forward<?>() | What you get |
|---|---|---|
| T& | & | T& |
| T&& | & | T& |
| T& | && | T& |
| T&& | && | T&& |
Note: The general recommendation is to use perfect forwarding for library code
because users can pass any argument types to the library.
Note You should try to constrain expected types where appropriate. The generic
implementation in code:perf-forward will accept any type for the argument
where you may only want T to be a string-type.
Warn: Be cautious about the application of forward references. Only where T is
being resolved can the type be a forward-reference. If T was resolved earlier
it's a R-value reference.
// A forward-reference.
struct foo {
template<typename T>
void foo(T&& t);
};
// A R-value reference.
template<typename T>
struct foo {
void foo(T&& t);
};
// A R-value reference.
template<typename T>
struct foo {
template<typename U>
void foo(T&& t);
};Variadic Templates
Templates taking an arbitrary number of T types.
This works recursively using a declaration called parameter packs. A parameter
pack is a template type declared as typename... Ts.
template <typename... Ts>
struct Foo {};
Foo<> f0;
Foo<int> f1;
Foo<int, double> f2;
Foo<int, double, Foo<std::string>> f3;Parameter packs are processed recursively with the template processing the head of the pack and then recursively processing the rest of it.
// Declare a base case, for when there's only one type.
template <typename T>
T sub(T head) {
return head;
}
// Declare a recursive case for >1 template types.
template <typename T, typename... Ts>
T sub(T head, Ts... tail) {
return head - sub(tail...);
}
auto n = add(10, 3, 2, 1); //=> 10-3-2-1
The expansion of a parameter pack (such as in sub(T head, Ts... tail)) supports
pattern expansion. Anything placed before the expansion is expanded for each
element of it.
template <typename... Ts>
void printAddresses(Ts... xs) {
variadicPrint(&xs...);
}
printAddresses(5, 10.5); // => variadicPrint(int&, double&)
You can determine the length of a parameter pack with sizeof...(Ts). If a
template takes multiple parameter packs they must have the same length.
Compile Time Expressions
Constant Expressions
Allow us to evaluate certain expressions at compile time. This could be useful for example to have an array whose size is defined by the result of a function call that can be calculated at compile time.
constexpr size_t MBtoB(int n) {
return n * 1024 * 1024;
}
int main() {
constexpr int numberOfMB = 1;
char nums[MBtoB(numberOfMB)];
std::cout << sizeof(nums) << std::endl; //=> 1048576
}The semantics for when a constexpr is evaluated aren't guaranteed to be at
compile time unless the expression it's used in is also a constexpr. For
example std::cout << MBtoB(10) may evaluate MBtoB at compile time or at run-time.
If the expression contains a non-constexpr parameter then it can only ever happen
at run-time: int i = getNum(); MBtoB(i);.
Static Assertions
Allow us to trigger a failure at compile time based on some constant-expression assertion. This is often useful in template programs to restrict the allowed subset of template parameters based on some traits.
class MyClass;
template <typename T>
struct is_cool {
static constexpr bool value = false;
};
template <>
struct is_cool<MyClass> {
static constexpr bool value = true;
};
template<typename T>
void doSomethingCool() {
static_assert(is_cool<T>::value, "Type T isn't cool enough for this");
}Type Inference
The auto keyword is a placeholder for whatever values satisfies the right hand
side of an expression.
int i = 0;
int & ir = i;
const int ci = 0;
const int &cir = 0;
// Auto deduces by value type, so lifetime modifiers are discarded
// when copying by value.
auto ai = i; //=> int
auto air = ir; //=> int
auto aci = ci; //=> int
auto acir = cir; //=> int
// You can attach a reference modifier to the auto declaration to inherit
// reference modifiers. This is needed otherwise you'd discard them.
auto &ri = i; //=> int&
auto &rir = ir; //=> int&
auto &rci = ci; //=> const int&
auto &rcir = cir; //=> const int&
// Any other specifiers are used with the actual type substituted as you'd
// expect.
const auto ci = i; //=> const int
const auto cir = ir; //=> const int
const auto cci = ci; //=> const int
const auto ccir = cir; //=> const int
// Pointers are a special case where the pointer asterisk is optional.
// You can include it for readability.
auto ip = &i; // => int*
auto* ip2 = &i; // => int*
auto ipp = &ip; // => int**
auto** ipp2 = &ip; // => int**
auto keyword.Declaring Expression Types
One downside of auto is that it may discard qualifiers such as references. If you
try to assign the result of an expression that is a reference, auto will copy
that reference by value and store it as the non-reference type.
For example:
int& getResult();
void foo() {
auto bar = getResult();
// What's the typeof bar? It's int.
// We copied the value returned by getResult (which is a reference)
// into a new variable of type int, where we intended to store an
// int&.
}For situations like this you can use decltype(expr) to reference the true result
type of expr.
decltype(getResult()) bar = getResult();
// Or even better, avoiding the code repetition.
decltype(auto) baz = getResult();Note: If you're curious why auto doesn't do what decltype does already, it most
likely is for simplicity reasons. Implementing auto was been easier than
implementing decltype so auto came first and decltype later and now the two work
cooperatively together.
std::vector<Person> persons;
// To create a collection of iterators over persons.
typedef std::vector<Person>::iterator PersonIterator;
std::vector<PersonIterator> iterators;
// Equivalently we can use decltype to automate.
using PersonIterator = decltype(persons.begin());
std::vector<PersonIterator> iterators;decltype vs typedef.Trailing Return Type c11
Sometimes with generic functions the return type is determined based on an expression of the parameter types. For situations like this we need to attach a trailing return type since the expression for it needs to know the names of the parameters.
// This is needed because a and b aren't declared until after the return // type is already specified. template<typename A, typename B> auto add(A a, B b) -> decltype(a + b) { return a + b; }Note: The trailing return type syntax is obsolete since C++14. Now simply
autoshould be able to deduce the value without any extra declarations.
Lambdas
Lambdas are a built-in way to declare short anonymous functions. Each lambda is filled in by the compiler as its own unique type. No two lambdas, even with the exact same parameter list or body, will have the same type.
// CAPTURE PARAM-LIST [-> RETURN-TYPE] { BODY }
const auto add = [](int a, int b) -> int {
return a + b;
};
// Return type can be inferred automatically and local variables
// can be captured into a lexical binding.
const int foo = 10;
const auto addFoo = [&foo](int a) {
return a + foo;
};Internally lambdas work by declaring an anonymous struct whose fields are
initialised from the capture arguments and that's given a operator()(...)
that has the same interface as the lambda type. Marking a lambda as mutable makes these
fields mutable.
Captures Reference
| Capture | Description |
|---|---|
[]{} | No captures |
[&]{} | Capture everything by reference |
[a]{} | Capture the variable a by copy |
[&a]{} | Capture the variable a by reference |
[&, a]{} | Capture everything by reference and a by copy |
[=, a]{} | Capture everything by copy and a by reference |
Argument Passing
The type of a lambda cannot be determined at runtime. The compiler fills in the lambda
definition with an equivalent class that stores the captured variables and
provides an operator() matching the lambda body. To allow passing a lambda to another
function you can use a template type for the function that the compiler will
fill in for you.
int foo = 5;
auto lambda = [&foo](int bar) -> int { return foo + bar; };
lambda(10); //=> 15
// The equivalent type the compiler will instantiate for this.
//
// Note: The type of a lambda is totally unique. Instantiating
// the same lambda more than once will lead to different types
// for each of them, even if they have the exact same signature.
struct lambda_anon_type {
int &foo;
lambda_anon_type(int &foo) : d_foo(foo) {}
int operator(int bar) { return foo + bar; }
}Generic Lambdas c14
Allows placing auto as a parameter type in a lambda and lets you create generic
lambdas.
#include <vector>
#include <numeric>
std::vector<int> ints = {1,2,3,4,5};
const auto add = [](const auto lhs, const auto rhs) {
return lhs + rhs;
};
std::accumulate(ints.begin(), ints.end(), 0, add); //=> 15
Note: A generic lambda parameter such as [](foo&&) is a forward-reference, not an
R-value.
Generalized Lambda Captures c14
You can also generate arbitrary data-members in the capture list for a generic lambda.
int m, n;
auto myLambda = [&i = m, j = n]{
// i is exposed as a reference to m.
// j is exposed as a reference to n.
};This can be useful to create mutable fields in the generated lambda struct and then allow the lambda to modify over them. For example:
auto counter = [i = 0]() mutable { return i++; }
counter(); //=> 0
counter(); //=> 1
counter(); //=> 2
counter(); //=> 3
counter(); //=> 4
View Types
Are light-weight wrappers (shallow copies) around data types such as std::string
that can be passed as read only views into those data-types very easily. This is
useful to avoid the overhead of cloning all the data on those types. View types
don't own the data they point to, they simply expose access to it.
Note: There's always the option to parameterise references to the desired type instead of passing a view into it, but this can be sub-optimal and may fail to compile if a cast to the desired type isn't possible.
Note: One could always use generics to approach this but that loses the nice interface of a concrete type (such as a substring operation on a string).
Warn: One danger of view types is that the underlying data may be modified after the view is created.
std::string str("foo bar")
std::string_view sv(str);
// error: This may reallocate the char* causing the
// existing view into it for ~sv~ to be modified.
str += "baz bag";To avoid this you should use views as parameters to functions and not persist their values beyond the lifetime of the function. By convention we don't pass views by reference because their shallow copies it's efficient to copy them repeatedly.
String View
std::string src = "watermelon";
std::string_view sv(src);
// This doesn't modify the actual string,
// it just shrinks our view into it.
sv.remove_suffix(5);
sv; //=> "water"
src; //=> "watermelon"
Iterators and Iterables
C++ iterators have an interface similar to pointers. You have an initial iterator pointing to the first element of a collection. You can increment the iterator to access the next element and you can compare a pointer against a final value which it equals when the iterator is finished.
const static int count = 10;
int nums[count] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for (int *it = nums; it != nums + count; ++it) {
std::cout << *it << '\n';
}This idiom for enumerating a collection by instantiating and moving across a pointer
like interface works across all standard collection types and even basic C arrays.
The standard library defines std::begin to return an iterator for the beginning of
a collection and std::end to return an iterator for the end. These are supported
by all collection types and most collections also provide member functions doing
the same thing.
int nums[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for (auto it = std::begin(nums); it != std::end(nums); ++it) {
std::cout << *it << '\n';
}std::begin and std::end instead.For Range Loop c11
Is a syntactical improvement which automates some of the boilerplate involved when iterating a conventional collection. All you have to do is specify a type for each element of the collection, a name to bind it to, and a collection to iterate.
int nums[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for (const int &it : nums) {
// Notice, no need to explicitly dereference the element.
std::cout << it << '\n';
}Conventions
Prefer Prefix to Postfix in Increment/Decrement Operators
When possible prefer prefix to postfix in increment and decrement operations. This is because postfix actually creates a copy of the object being incremented and then returns it, but if the goal is simply to perform an increment or decrement then this would be unnecessary. Just increment and return the original value.
Foo &Foo::operator++() { // called for ++i
this->data += 1;
return *this;
}
Foo Foo::operator++(int ignored_dummy_value) { // called for i++
Foo tmp(*this); // variable "tmp" cannot be optimized away by the compiler
++(*this);
return tmp;
}Equality Operator as a Friend Function
Can be implemented as a member function or a friend function.
class Foo {
public:
bool operator==(const Foo &other);
// OR
friend bool operator==(const Foo &a, const Foo &b);
};The latter form is preferred because the argument types, if implicitly converted,
will both be converted. On the other hand for the member function the argument type
may-be implicitly converted but the containing object (this) will not be.
Standard Library
CPP added a standard library in C++98. Before that all classes and functions were
defined in the global namespace. To mark this turn the CPP standard removed the
.h suffix from standard headers so now you'll find both <vector.h> and <vector>
available as includes. In general the .h versions are kept for backward
compatibility, but you should use the newer non-.h versions.
iostream
Is the standard streams library for C++.
It exposes functions for creating generic streams that can be read from and written into, including with automatic type conversions.
#include <iostream>
std::ifstream ifs("/file/path/foo.txt");
if (!ifs.good()) {
throw std::runtime_error("Failed to open file");
}
// Reading each line from the opened file stream.
std::string line;
while (getline(ifs, line)) {
std::cout << line << '\n';
}
// Reading numbers using >> operator and outputting them with minimum
// two character width and '0' padding to the left (%02d).
int number;
while (ifs >> number) {
std::cout << std::setfill('0') << std::setw(2) << number << '\n';
}Warn: If a read fails, it doesn't mean the previously read value of a variable has been reset. Always check after a read whether the stream is falsy in which case the read failed.
The stream API is very generic. You pass objects such as setfill and setw to
configure formatting for later arguments such as number. The API even accepts
functions. std::endl is a function and when passed to a stream, it is actually
passed as a function pointer, and the operator<< handler will call the function.
Warn: Avoid usage of std::endl. It causes the output stream to be flushed, which
can have noticeable performance costs. Prefer '\n' when possible.
strstream
Is a generic class for constructing strings as streams.
#include <sstream>
std::stringstream ss;
ss << 100 << ' ' << 200;
ss.str(); //=> "100 200"
int foo, bar;
ss >> foo >> bar;
foo; //=> 100
bar; //=> 200
vector
Is a variable length collection type for CPP which uses continuous fixed length arrays under the hood. Vector assumes the collection type is copy constructable and copy assignable.
#include <vector>
std::vector<int> vec;
vec.empty(); //=> true // Empty at initialisation
// Add elements to the end of the vector, allocating more
// memory for it if the capacity of the vector is exhausted.
vec.push_back(5);
vec.push_back(10);
vec.push_back(8);
vec.size(); //=> 3 // How many elements are in the vector
vec.capacity(); //=> ? // How many elements the vector can currently store,
// essentially how much space the underlying array has
// been allocated by vector.
vec[0]; //=> 5 // Lookup, doesn't check the bounds of the vector.
vec.at(0); //=> 5 // Lookup, throws std::out_of_range if out of bounds attempt
vec.front(); //=> 5 // Fetch first element in the vector
vec.back(); //=> 8 // Fetch last element in the vector
// A variant of push back which temporary object construction.
//
// For a user defined type such as Tuple<u,v> with a constructor
// taking two arguments: emplace_back(u,v) is equivalent to
// push_back(Tuple(u,v)). This works using [[https://en.cppreference.com/w/cpp/language/new#Placement_new][placement new]].
vec.emplace_back(10);
// Dereference the value at the end of the vector. This doesn't return the popped
// value because... TODO why? http://www.gotw.ca/gotw/008.htm
vec.pop_back();
// Dereference all the elements from the vector.
vec.clear();
// Raise the capacity such that it can store upto 1000 elements.
vec.reserve(1000)
// Accumulate all the values in vec, notice use of ~size_type~.
int sum;
for (std::vector<int>::size_type i = 0; i < vec.size(); ++i) {
sum += numbers[i];
} // sum => 33
vec.begin(); // Gives an iterator pointing to the first element of a container.
vec.end(); // Yields an iterator pointing to one past the last element in the container.
// You can use this to check whether a search on the container exhausted all
// possible entries and failed.
// Note: It's guaranteed that for an empty container vec.begin() == vec.end().
Erase-Remove Idiom
Is an idiom for iterable collections which allows deleting elements from the
collection. With Erase-Remove we use remove to move values satisfying some
predicate to the end of a range and then call erase to delete values from that
range forward them.
Note: Remove doesn't necessarily move values to the end, instead it overwrites earlier values that are to be erased with later values, and leaves junk data (most likely the original to-be-removed values) in the to-removed position.
std::vector v;
v.push_back(10);
v.push_back(3);
v.push_back(3);
v.push_back(9);
// Remove all values equal to 3 from the collection
std::vector<int>::iterator after = std::remove(v.begin(), v.end(), 3);
v; //=> {10, 9, ?, ?}
v.erase(after, v.end()); // Actually erase from the collection
v; //=> {10, 9}
list
Provides a doubly linked list implementation that's mostly compatible with the
vector API, except it also provides a push_front operation.
#include <list>
std::list<int> list;
list.push_front(5);
list.push_front(10);
list.push_front(8);
list; //=> 8, 10, 5
tuple
Provides an arbitrary length finite collection of distinct possible types.
#include <tuple>
std::tuple<int, double> tup = std::make_tuple(5, 5.5);
// std::tie creates a tuple of l-value references and you can assign a
// tuple of matching types from an R-value to update the L-values.
int i;
double j;
std::tie(i, j) = tup;
// std::tuple_cat concatenates to tuples together element wise.
std::tuple<int, double, const char*, int> tup2 =
std::tuple_cat(tup, std::make_tuple("foo", 9));
// Tuples support element wise comparison and equality operators.
tup <= std::make_tuple(5, 5.6); //=> true
utility
pair
#include <utility>
std::pair<double, int> pair(5.4, 3);
// Note: pair does provide a default constructor but that only works
// when both of the pair types also provide a default constructor.
p.first; //=> 5.4
p.second; //=> 3
// make_pair is a helper that constructs a pair from its argument
// types. This was mostly useful pre-C++17 where you didn't get
// automatic type-deduction for class templates.
std::make_pair(5.4, 3) == pair; //=> true
map
Is an ordered key-value collection type.
The standard requires most map operations to have \( \mathcal{O}(N \log N) \), so their typically implemented as a self-balancing binary tree (red-black trees commonly).
#include <map>
std::map<std::string, number> ages;
ages.insert(std::make_pair("Mohsin", 22));
ages.find("Mohsin")->second; //=> 22 // Return an iterator to the pair with first="Mohsin"
ages.find("Alicia") == ages.end(); //=> true // Failed to find entry with key
ages["Meelak"] = 5; // Assign to an existing pair or create a new one
ages["Nishom"] + 5; //=> 5 // Automatically creates and saves a default pair for missing
// entries (but requires value type to be default constractable)
ages.erase(ages.find("Nishom")); // Remove a value from a map.
iterator
std::vector<int> nums;
// All iterable collection types expose iterator types within their namespaces.
std::vector<int>::iterator it = nums.begin();
std::vector<int>::const_iterator itc = nums.cbegin(); // Read only iterator
// You can iterate through a collection using an iterator, similair to a pointer.
for (std::vector<int>::iterator it = var.begin(); it != var.end(); ++it) {
std::cout << it << std::endl;
}| Iterator Category | Capabilities |
|---|---|
| Random Access | [], +=, -=, +, -, <, <=, >, >= |
| Bidirectional | -- |
| Forward | Multipass |
| Input | ->, ==, != |
| Output | Copy constructor, =, *, ++ |
algorithm
Provides a suite of useful and reliable algorithms.
std::vector<int> v(3);
v.push_back(10);
v.push_back(0);
v.push_back(3);
std::sort(v.begin(), v.end()); // Sort in iterator range from start to end of vector.
v; // {0, 3, 10}
std::vector<int> v, result;
v.push_back(-3);
v.push_back(-2);
v.push_back(2);
std::transform(v.begin(), v.end(), std::back_inserter(result),
// Cast needed because compiler needs to know which
// overload it should target.
static_cast<double(*) double>(std::abs));